mysql-实战-优化
数据库驱动、数据库连接池、MySQL 的连接池
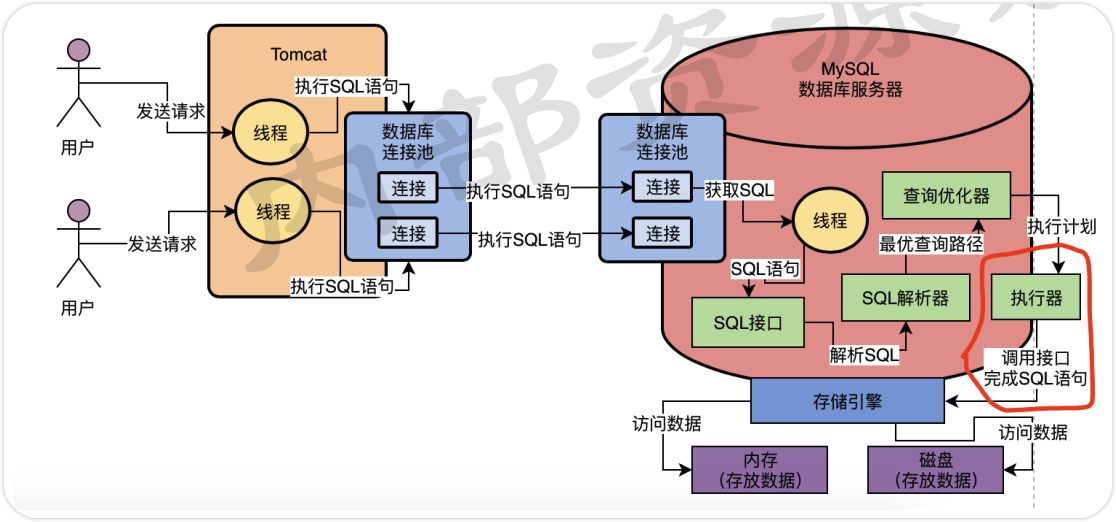
一个不变的原则:网络连接必须让线程来处理
SQL 接口:负责处理接收到的 SQL 语句
查询解析器:让 MySQL 能看懂 SQL 语句
查询优化器:选择最优的查询路径
调用存储引擎接口,真正执行 SQL 语句
执行器:根据执行计划调用存储引擎的接口
InnoDB 的重要内存结构:缓冲池(Buffer Pool)
对 Buffer Pool 进行调整
[server]
innodb_buffer_pool_size
数据页:MySQL 中抽象出来的数据单位
磁盘文件中有很多的数据页,每一页数据里很多行数据磁盘上的数据页和 Buffer Pool 中的缓存页是如何对应起来的?
默认情况下,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应,都是 16KB。缓存页对应的描述信息
描述信息本身也是一块数据,在 Buffer Pool 中,每个缓存页的描述数据放在最前面,然后各个缓存页放在后面。描述信息包括:这个数据页所属的表空间、数据页的编号、这个缓存页在 Buffer Pool 中的地址等等其他信息。怎么知道哪些缓存页是空闲的?(free 链表)
free 链表,是一个双向链表数据结构,free 链表里,每个节点就是一个空闲的缓存
页的描述数据块的地址,也就是,只要一个缓存页是空闲的,那么他的描述数据块就会被放入这个 free 链表中。怎么知道数据页有没有被缓存?
数据页缓存哈希表的结构。哪些缓存页是脏页?
flush 链表,这个 flush 链表本质也是通过缓存页的描述数据块中的两个指
针,让被修改过的缓存页的描述数据块,组成一个双向链表。淘汰缓存数据
引入 LRU 链表来判断哪些缓存页是不常用的。
使用简单的 LRU 链表的机制,其实是漏洞百出的,因为很可能预读机制,或者全表扫描的机制,都会一下子把大量未来可能不怎么访问的数据页加载到缓存页里去,然后 LRU 链表的前面全部是这些未来可能不怎么会被访问的缓存页!基于冷热数据分离的思想设计 LRU 链表
参数 innodb_old_blocks_pct触发 MySQL 的预读机制
参数 innodb_read_ahead_threshold、innodb_random_read_ahead
多线程并发访问一个 Buffer Pool,必然是要加锁的,然后让一个线程先完成一系列的操作,比如说加载数据页到缓存页,更新 free 链表,更新 lru 链表,然后释放锁,接着下一个线程再执行一系列的操作。
- 配置多个 Buffer Pool 优化并发能力
参数 innodb_buffer_pool_size、innodb_buffer_pool_instances - 基于 chunk 机制支持运行期间动态调整 buffer pool 大小
undo 日志文件:如何让你更新的数据可以回滚
Redo Log Buffer:万一系统宕机,如何避免数据丢失
redo 日志,记录对数据做的修改
交事务的时候将 redo 日志写入磁盘中
三种 redo 日志刷盘策略优缺点
MySQL binlog
redo log,偏向物理性质的重做日志
binlog 归档日志,记录的是偏向于逻辑性的日志
binlog 不是 InnoDB 存储引擎特有的日志文件,是属于 mysql server 自己的日志文件。
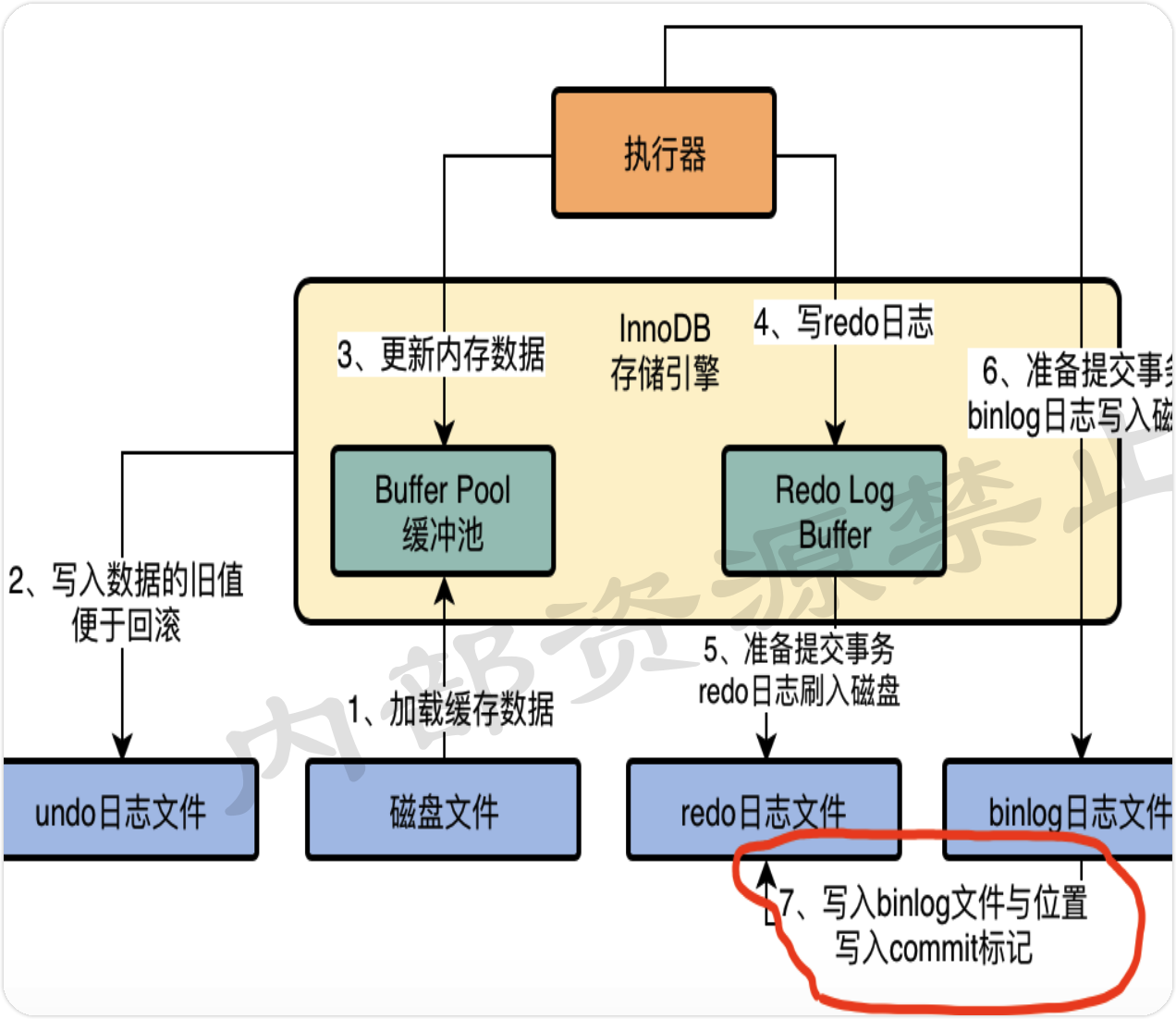
执行器是非常核心的组件,负责跟存储引擎配合完成一个 SQL 语句在磁盘与内存层面的全部数据更新操作。
上图更新语句的执行,拆分为了两个阶段,1、2、3、4 几个步骤,本质是执行这个更新语句的时候干的事。
5 和 6 两个步骤,是从提交事务开始的,属于提交事务的阶段。
5、6、7 三个步骤,必须是三个步骤都执行完毕,才算是提交了事务。
在 redo 日志中写入 commit 标记的意义
保持 redo log 日志与 binlog 日志一致
binlog 日志的刷盘策略
sync_binlog 参数
基于 binlog 和 redo log 完成事务的提交
后台 IO 线程随机将内存更新后的脏数据刷回磁盘
QPS.TPS、IOPS、吞吐量、latency
数据库压测工具:sysbench
检测机器(Linux)性能 top 命令
对数据库监控 Prometheus+Grafana